

バーチャル3Dクリエイター神部まゆみです(*^_^*)
この記事はChatGPTの画像生成機能を試してみたので、それについての記事です。
前回Stable Diffusin のForgeを使ってみたけど、手軽さはChatGPTが一番かな…と思った。

なんかChatGPTでベースを作って使い分けていくと良いっぽい?けど。
現在、400個以上の人気Unityアセットが50%オフで買える Unityサマーセールをやってるみたいです(2026/07/07まで)。

日替わりでアセットが90%オフになっているので、欲しいアセットはこの機会に買っておくと良いかも。

BOOTHでVRoidテクスチャやVRChat向けオブジェクトなどを販売しています。いいねしてくれると励みになります(*^-^*)
ChatGPTの画像生成機能について
昔のChatGPTはメタ認知能力が低かったのか、ChatGPT自身のことを聞いても頓珍漢な回答が返ってきた覚えがあるけど…今は大丈夫っぽいので彼に聞いてみます。

ChatGPTの画像生成機能について、概要と他サービスと比較したウリを教えてください。
今のChatGPTの画像生成は、昔の「DALL·Eを呼び出す別機能」ではなく、GPT-4oに統合された“会話型画像生成”になっています。
普通に会話しながら、
- 「もう少し可愛く」
- 「髪を柔らかく」
- 「このキャラのまま」
- 「背景だけ変えて」
みたいな修正を、そのまま文脈込みで続けられるのが大きな特徴です。
ChatGPT画像生成の概要
特徴を一言で言うと:
「画像生成AI」より、“画像を扱えるChatGPT”
という感じです。
例えば:
- テキストで会話
- 画像アップロード
- i2i
- 修正指示
- デザイン相談
- UIモック作成
- 漫画やバナー生成
などを、全部会話の流れでできます。
特に:
「この画像をベースに調整して」がかなり強いです。
今回みたいに:
- VRoid画像
- 雰囲気アップ
- anime寄り
- 髪質改善
- 柔らかい光
などを、自然言語だけでかなりいい感じに寄せられます。
他サービスと比べた最大のウリ
1. 会話しながら修正できる
これが最大。
MidjourneyやStable Diffusionは:
- prompt職人
- パラメータ調整
- seed管理
がかなり必要。
一方ChatGPTは:
「もう少し笑顔で」
「猫っぽさ増やして」
「前の絵の雰囲気で」
みたいな曖昧指示が通りやすい。
2. i2iが自然
Stable Diffusion系は:
- denoise
- CFG
- sampler
- ControlNet
など知識が必要。
ChatGPTは:
- 元画像アップ
- 口頭指示
だけでかなり動きます。
初心者への敷居がかなり低い。
3. 文字に強い
これは今かなり重要。
昔の画像AIは:
- 崩れた日本語
- 意味不明英語
が弱点でした。
GPT-4o系は:
- ロゴ
- UI
- ポスター
- サムネ
- 説明図
などで文字がかなり改善されています。
4. “理解力”が高い
例えば:
「VTuberっぽく」
「柔らかい夕方の光」
「青春アニメ風」
みたいな抽象表現。
ここがかなり強い。
単なる画像生成というより:
“文脈理解”
が強いです。
ChatGPT画像生成の立ち位置
かなり今っぽく言うと:
| サービス | 向いてる用途 |
|---|---|
| ChatGPT | 会話しながら作る |
| Midjourney | 一発で映える |
| Stable Diffusion | 自由に作り込む |
です。
特にChatGPTが強い人
かなり向いてるのは:
- アイデア出し
- ブログ
- SNS
- VTuber
- キャラデザイン
- サムネ
- ラフ制作
- 雰囲気調整
など。
一方で苦手な部分
完全キャラ固定
例えば:
- 同じキャラを100枚
- 厳密な衣装固定
- LoRA学習
- dataset作成
はStable Diffusion系が強い。
動画はまだ専業サービス優勢
瞬きや髪揺れ程度は可能でも、
- 長尺
- 高FPS
- ダンス
- 一貫性
はまだ:
- Kling
- Runway
- Sora
- ComfyUI workflow
などが強いです。
実際かなり増えてる使い方
最近は:
ChatGPT
→ ラフ・方向性・雰囲気
↓
Stable Diffusion
→ キャラ固定・量産
↓
動画AI
→ MV化
みたいなハイブリッド運用がかなり多いです。
VRoidのi2i用途で試してみる
AI画像と言ってもあくまで私のVTuber活動縛りで使いたいため、私のVRoidモデルをi2iして使う用に使っていきたい。
AI絵師の人でも特定のキャラだけ出力して縛りを設けている人は一途で好感が持てますね…。
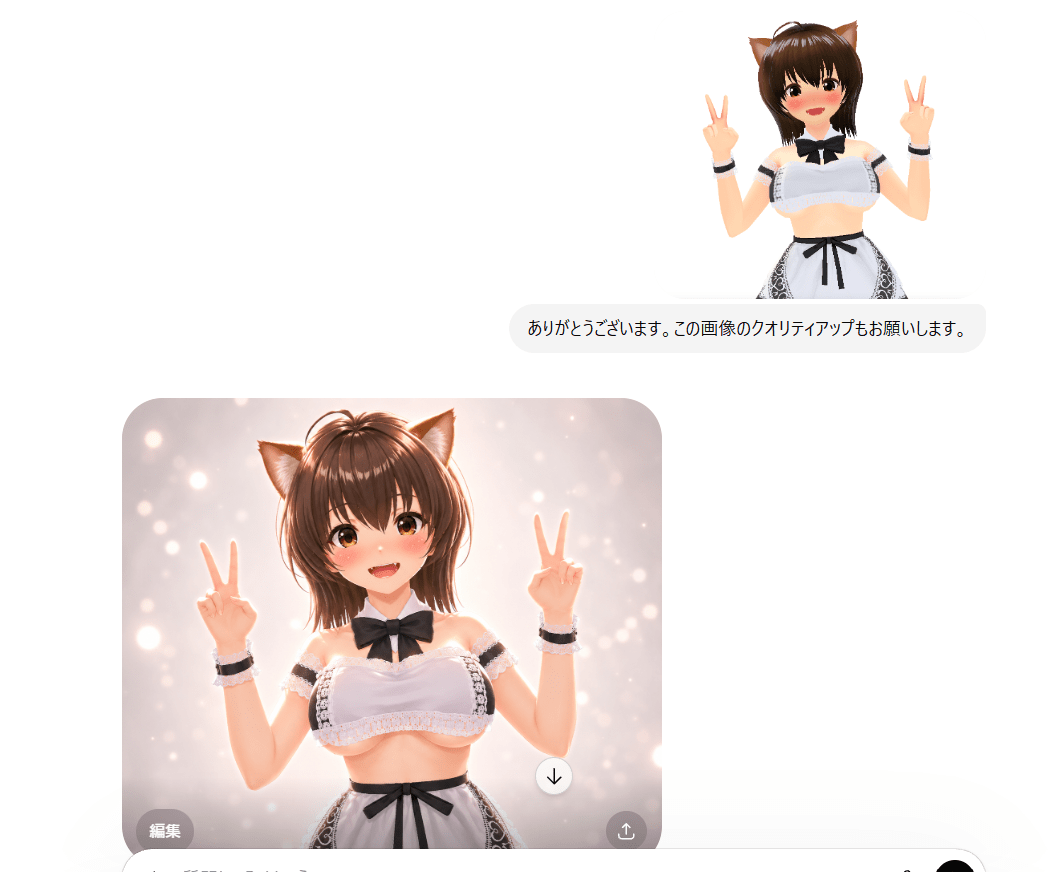
VRoidの画像をクオリティアップする
これは前回の記事でやったけど、キャラの特徴を踏まえつつ完璧にクオリティアップしてくれましたねΣ(゚Д゚)
顔の比率、髪型、目のパーツなども保ったままでクオリティを上げてくれた。

角度を変えたり服に文字が書いてあっても普通に行けた。

うーんこれはなかなか…( *´艸`)指も破綻せずちゃんと5本ですね。

背景を透過させる
透過もやってみたけどちゃんとやってくれました。


しかし透過=服を透けさせる=エロと誤解釈され、拒否されることもあるっぽい?
ダメならプロンプトを変えたりすると良いかも。
服装を変える
↑の画像の服装を変えてみます。

おお完璧だΣ(゚Д゚)

まぁi2iした後の画像を改変しているから、VRoid縛りで行くならVRoidでセーラー服画像撮ってからのほうが良いかな?
Unityに配置してポーズを撮らせてやる
VRoidをVRMエクスポートして、UniVRMを使えばUnityに持って行けます。
背景はシンプルなほうが良いっぽいので、適当に平面をキャラの後ろに持ってきて、影の影響を受けない Unlit/Color などのシェーダーにすると良い感じです。
Very Animationで適当にポーズをとらせる。
まぁこんなもんかな。
VRoidのブレンドシェイプにデフォルトで含まれている、Fangだっけ、八重歯っぽいやつを出すやつも使った。

おお、これはなかなか( *´艸`)

ちゃんと八重歯とか細かい部分も拾ってくれていますね。
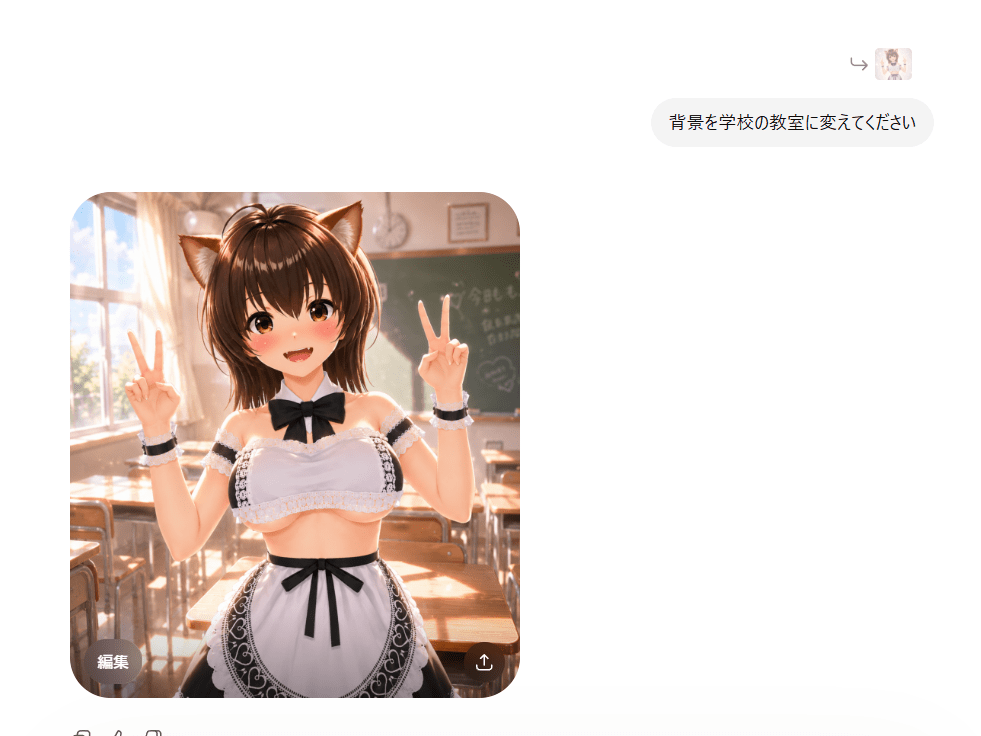
背景を変える
これ背景は別に生成して、背景無地で生成して貰って後で合成するのも良いみたいだけど。
まぁ普通に背景を変えてもらいます。
…おお簡単にできたΣ(゚Д゚)
まったく凄い時代になったもんだぜ…(;゚д゚)ゴクリ

背景にモブの男子学生を追加する
ちょっと寂しいから背景にモブの男子学生を追加して、オタサーの姫っぽくするか…。
おお、簡単に追加できたΣ(゚Д゚)


ちょっとさわやかすぎるためキモオタっぽくしようとしたが…
なんかコンテンツポリシーに反するとかでダメだった。キモオタが差別用語と解釈されたか…?
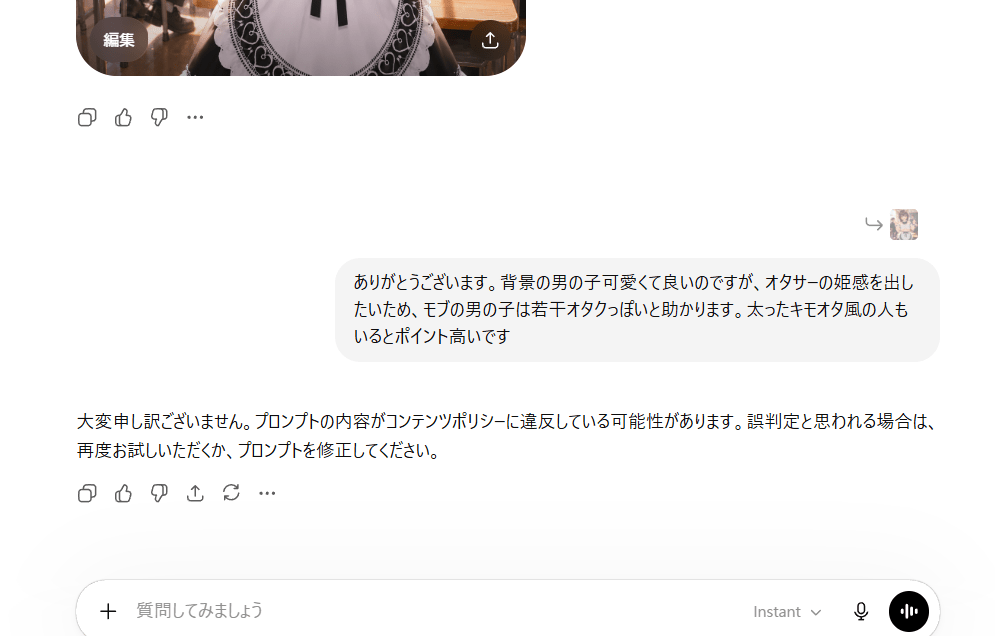
オブラートに包んでプロンプトを書いたら行けました!これめっちゃ良い感じにオタサーの姫感が出ていて良いかもw


んーこれよくできたな…。エロじゃないから伸びなさそうだけどPixivにアップしてみようかな。AIタグをつけて。
追記:アップしたら普通に伸びなかったけど、AIだからかフォロワー減りました(^_^;)アカウント分けたほうが良さげ。
そもそも手書きでもオリジナルはエロ以外伸びにくいようなので、伸ばしたいならエロだけにしたほうが良いか…。
文字が入っててもいける
前作った文字入り画像も行けた。あまり変わらないが…。


文字の改変も行ける
せっかくなので文字の改変も試してみます。
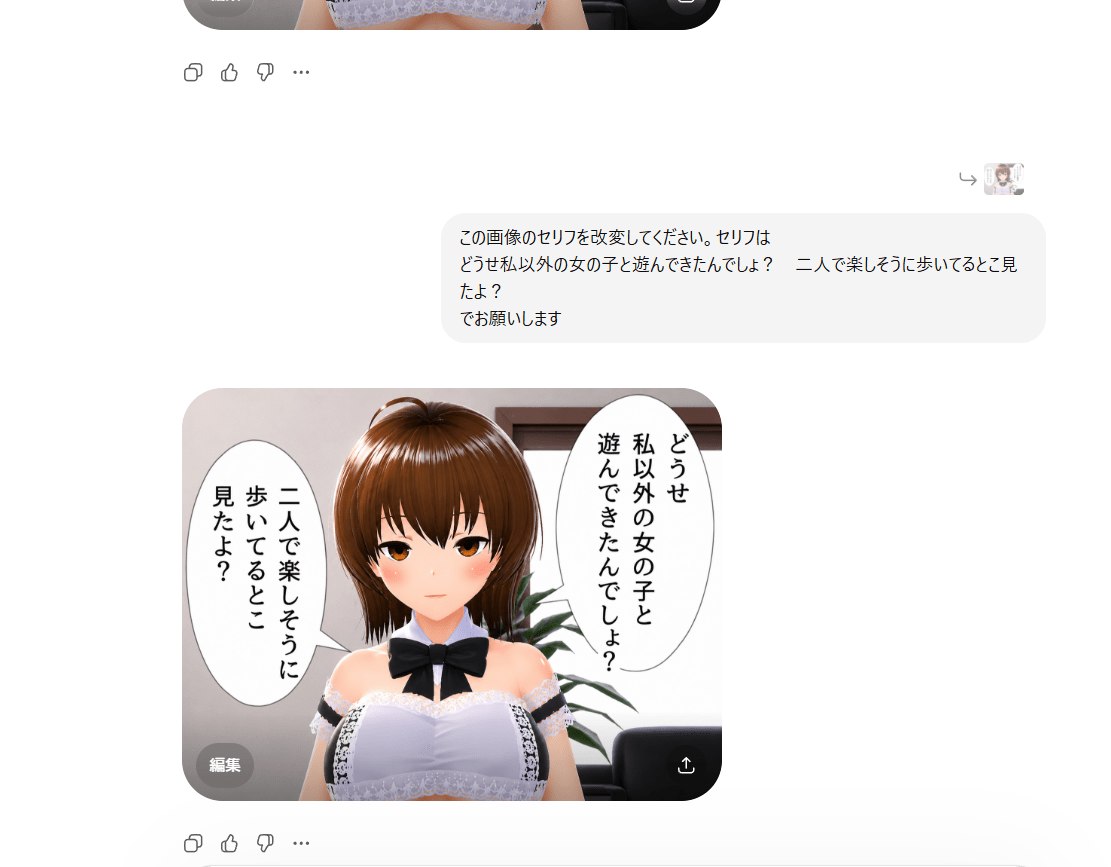

若干はみ出たけど追加で指定すればいけるかな?
まぁこのくらいならサクッと作れるので助かりますね。
吹き出しから追加してもらおうとしたが…
以前作ったこの画像をクオリティアップして、
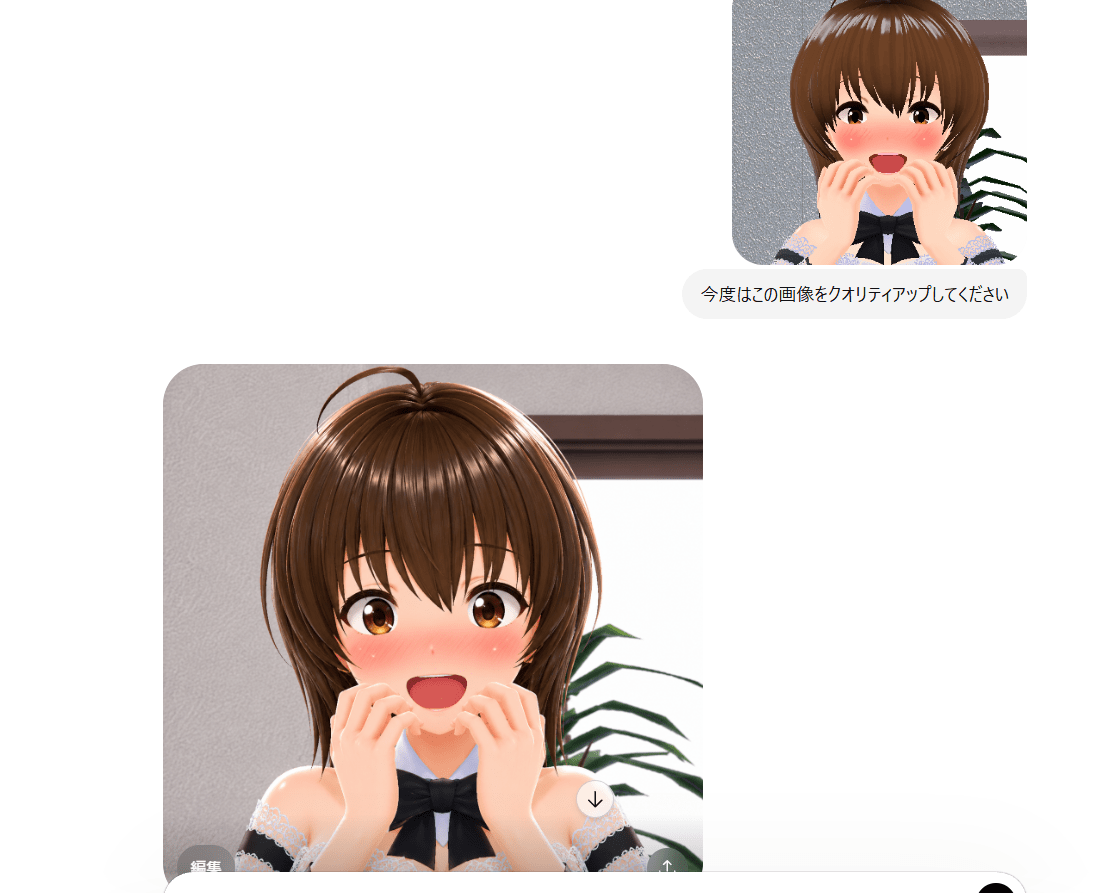
左右に吹き出しとセリフを追加してもらおうとしたけど…なんかコンテンツポリシー違反とやらでダメだった(-_-;)
最初は「えーまじDT!?」にしようとしてDTで引っかかったのかと思ったけど、別のセリフに変えてもダメだった。謎。
結局セリフを短くしたら生成できました。プ〇キュアのほうがコンテンツ的にヤバそうだけど(笑)、吹き出し一つだから大丈夫だったとか?
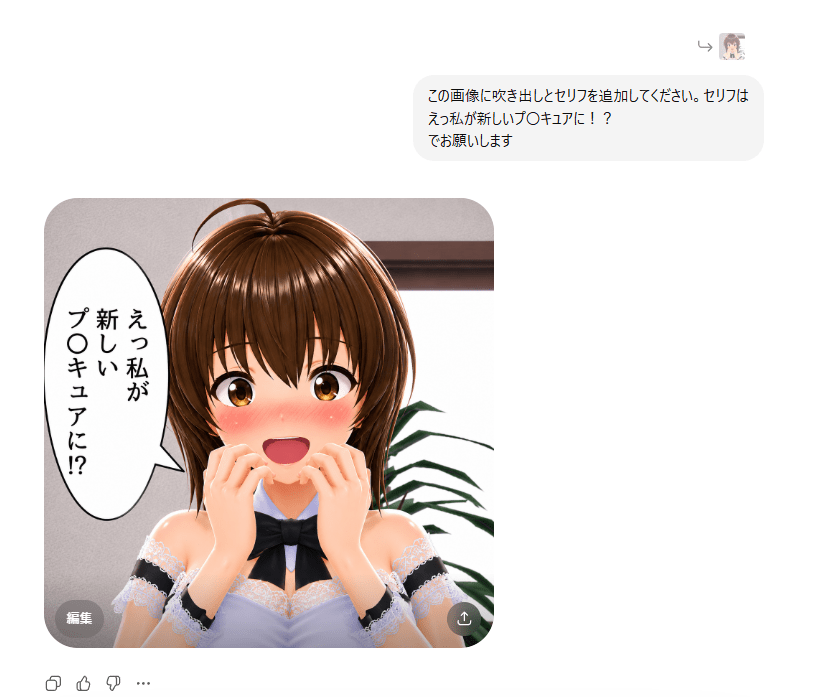

しかし社会人でもプリキュアになれるんだろうか?いやちょっとキツイか…(^_^;)
複数キャラでも行ける
ChatGPTパイセンによると、キャラの距離がある程度離れてれば成功率高いっぽいけど…。
このくらい密着してても行けるか?

というかどこまでセーフなんだろう?おねショタは児童ポルノでダメとかあるのだろうか?(^_^;)
…と思ったけど普通に行けましたね。


ChatGPT、やはりAI業界のトップランナーだから、どういう画像なのか解釈するのが上手いな(^_^;)
密着してると体の一部と誤解釈されてとんでもない画像が出てくるかと思ったけど、ちゃんとやってくれました。
左にVRoidの三面図、右に参考イラストを提示してi2i ※強力だが権利関係に注意
あとは左にVRoidの正面、側面、背面の三面図を提示して、右側に参考イラストを提示してi2iする方法もあります。


PureRefっていうアプリを使うと画像をD&Dして、簡単にこういう配置を作りやすいです。

しかしこれインスパイア元のイラストの絵師さんとしては「勝手にi2iするな🤬」ということになるし、権利関係的にちょっとアレかな…。
そもそもAIの仕組み自体が勝手に学習したデータを使っている感じだし、あまり大っぴらにはできないが…。
インスパイア元の画像へのリンクを貼って結果を掲載しようと思ったけど、絶対「勝手にAIに食わせるな🤬」ってことになると思うのでやめておきます(-_-;)
ほぼ完璧にキャラを変えて生成できたけど、やるならご自身でお試しください。
まぁどうせAIイラストとして投稿するならそのあたりは覚悟のうえでやると思うけど、無難に行くなら自分でText to Imageで出力したAIイラストをお手本にしてi2iする方が良いかな…?
お手本画像は裸じゃなければ割となんでもいけるかな?
ChatGPTはエロ系の画像はダメっぽいけど、聞いてみたら水着やキス画像とかはまぁOKみたいなことを言っていた。
まぁ身も蓋もないことを言えば、エロ系の画像と言っても単に裸で乳首や陰部が映っているというだけなので、そこを塗りつぶすか着衣i2iした画像をお手本に使えば同じような構図で生成してくれるとは思います。
せっかく3Dをやっているのだから参考にしてUnityで作ったほうが良いか…
クリーンに行くならば、構図だけ参考にしてVRoid+Unityで似たような構図を再現してスクショ、ChatGPTにクオリティアップや背景追加などをしてもらって作るのが良いかな。
まんまi2iだとパクリになってしまうし、創意工夫を何もしていないのでちょっとね(-_-;)
まぁイラストは見栄えを良くするために現実ではありえない嘘がたくさん入っているので、経験上3Dでトレスしようとしても別物になることが多いけど。
でもそこにオリジナル性が出てくると思うので、VRoidやUnityが使える人は他人のイラストを参考にするくらいが良いかな。
ChatGPTはエロ系の画像はダメっぽい
水着くらいまでは行けるっぽいけど裸の画像とかはダメっぽいですね。まぁ当たり前だけど(^_^;)
Stable Diffusionのインペイントで服を塗りつぶして生成したら裸にできたけど、組み合わせてやるしかないかな。
ChatGPTは適当な文章指定だけで上手くやってくれるからエロ系にも使えれば最強かと思ったけど、アダルトモードも延期されたっぽいし実現するのかは不明w
ChatGPTの絵柄は可愛くてかなり好みなのだけど…。まぁそっちはローカルでやるのが良いかな。
おわりに
んー、さすがChatGPTは精度高くてクオリティも高いですね。
しかしどこまで行ってもAI絵でしかないため、嫌われてしまう傾向にあるけど…。
Pixivのアカウントに投稿してみたらフォロワー減ったし、投稿していくならアカウント分けたほうが良いと思う。
えっちなやつにしたいならこれでベース作ってローカルのやつでやるのが良いかな…。
ChatGPTは大雑把な指定でも良い感じに仕上げてくれるし、絵柄が可愛いので使い勝手が良いですね。
このためだけに課金してChatGPT Plusにしても良いかもしれません。
また何かあれば追記します(*^_^*)